
В WordPress изменится метод, используемый для предотвращения индексации сайтов со стороны поисковых систем. Ранее после выбора опции «Запретить поисковым системам индексировать сайт» на странице Settings – Reading в WordPress добавлялась строка Disallow: / к файлу robots.txt. Это помогало запретить краулинг (сканирование), однако сайт все равно мог появляться в поисковых результатах.
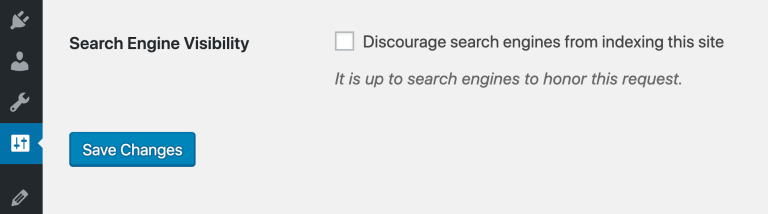
В WordPress 5.3 вместо метода с robots.txt появится обновленный мета-тег meta name=’robots’ content=’noindex,nofollow’. Мета-тег позволяет надежнее предотвратить индексацию и последующий краулинг сайта.
Параметр, запрещающий поисковым системам индексировать сайт, нередко воспринимался пользователями как способ скрыть свои сайты из выдачи. Однако он не всегда работает именно так. Джоно Алдерсон резюмировал проблему и предлагаемое решение в комментарии к тикету, связанному с данным изменением:
«Параметр Reading предназначен для того, чтобы предотвратить индексацию контента поисковыми системами. При этом краулинг все равно остается разрешенным. Наличие правила disallow в robots приводит к тому, что поисковые работы не добираются до директивы noindex и потому могут индексировать «фрагменты» (когда страница индексируется без контента).
Специалисты Google недавно объявили о том, что они прилагают все усилия для предотвращения индексации фрагментов. Однако пока этот вариант возможен, мы должны скорректировать текущее поведение. Давайте удалим правило disallow из robots.txt и разрешим Google (и другим поисковым системам) сканировать сайт»
В заметке, связанной с изменением, Питер Уилсон порекомендовал разработчикам, желающим запретить индексацию разрабатываемых сайтов, добавить HTTP-заголовок X-Robots-Tag: noindex, nofollow при передаче всех ресурсов сайта, включая изображения, PDF, видео и другие ресурсы.
Источник: wptavern.com







Здравствуйте, Дмитрий! Есть простой вопрос для Вас по поводу robots.txt. У меня есть правило: Disallow: /wp- — запретить индекс папок с wp-. Но если я ниже поставлю правило Allow: /wp-content/pages — в этой папке у меня отдельные html страницы. Будет ли индексация их или первое правило всё запрещает?
Allow всегда имеет приоритет для робота. В случае если даже будут конфликты, Allow все равно будет в приоритете.
Т.е. в вашем случае индексация /wp-content/pages будет производиться. Кстати, место размещения в тексте не важно (выше или ниже).
Если что, вот еще вам на заметку. Там же есть и ссылки на разные пруфы.
https://stackoverflow.com/questions/4589431/robots-txt-priority-question
Благодарю, Дмитрий! Как всегда, Ваши ответы на высоте и по скорости, и по качеству! ;)
Спасибо!)